注:近日,金電聯行首席科學家曹鴻強在天堂硅谷信息技術閉門會上做了精彩發言,以下根據其講話實錄整理而成。

感謝主辦機構。很高興有這個機會,和大家分享金電聯行在大數據領域的一些觀點和做法。
首先介紹一下公司的情況。金電聯行有兩個顯著標簽:一是國內大數據行業領軍企業之一。公司成立于2007年,是國內最早涉足大數據行業的高新技術企業,經過多年發展,在金融大數據、政務大數據、產業大數據的部分細分領域已經位居全國領先地位。二是國內信用建設主導企業之一。我們是國內最早運用大數據技術開展信用體系建設的企業,是中國人民銀行首批備案的全國性企業征信機構、北京征信機構總經理聯席會主席單位;是國家發改委綜合信用服務試點機構、第三方評估機構;是工信部、科技部等主管單位認定的信用體系建設和中小微企業信用融資評價機構;國家公共信用信息中心第一批可為信用修復申請人出具信用報告的信用服務機構。
作為一家大數據企業,金電聯行有一個基本觀點:大數據正在推動流程化系統向決策支持系統轉變。在IT領域,如果說過去二三十年是流程化系統占據主導地位,那么未來二三十年一定是決策支持系統占據主導地位,要用數據說話,要讓數據說話。
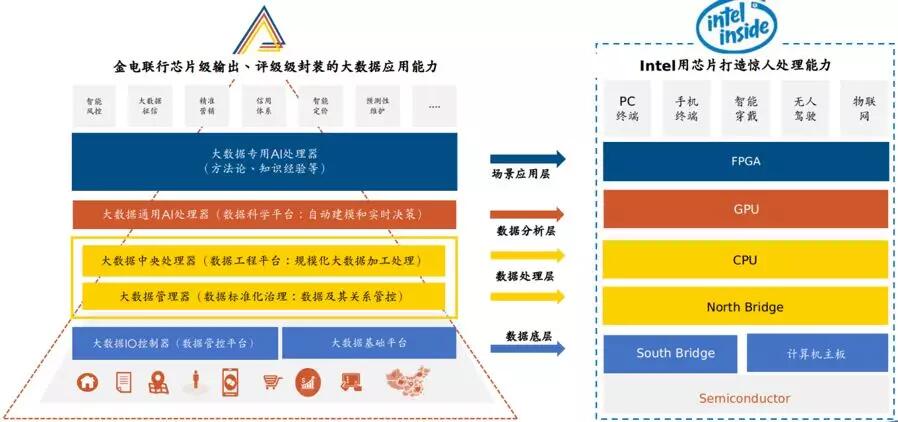
因此,金電聯行將核心業務能力定位為幫助客戶實現決策支持系統。經過在金融、政務、產業等市場十多年領域的技術積累,我們建立了覆蓋大數據價值變現全鏈條的五層架構(如下圖所示):最底層是大數據輸入輸出控制器和大數據基礎平臺,其中前者實現大數據的內外交換及其控制,例如安全、計費等,類似計算機的南橋芯片;后者是大數據存儲、處理、分析的基礎設施,類似計算機的主板。倒數第二層是大數據管理器,實現了大數據的數據管控,例如數據標準、元數據、數據質量、數據譜系等,類似計算機的北橋芯片。中間一層是大數據中央處理器,即針對大數據的數據工廠平臺,實現規模化的大數據加工處理,類似計算機的CPU芯片;再往上是大數據通用AI處理器,即針對大數據的數據科學平臺,實現規模化的大數據分析挖掘,類似計算機的GPU芯片。最上面一層是大數據專用AI處理器,固化業務專家的方法論和知識經驗,實現面向特定領域的大數據分析挖掘,類似計算機的FPGA芯片。這五層架構作為一個整體,支撐信貸風控、精準營銷、社會治理、企業征信、智能定價、預測性維護等各種具體大數據決策支持應用,類似計算機作為一個整體支撐各種軟件應用。當然,有可能五層架構的某個部分是客戶自研的,或者是友商的,例如大數據基礎平臺。我們的五層架構是開放的,有對外的兼容性。金電聯行大概就是這樣一個產品和技術架構,我們認為,這個架構是建設決策支持系統(包括開發和運維的全生命周期)的一條有效路徑。
在二十多年前讀書的時候,我曾經學過一門課程,叫計算機輔助軟件工程,英文縮寫是CASE。如果大家都認可,決策支持系統是一種特殊的IT系統,大數據處理和分析軟件是一種特殊的軟件,那么我們的五層架構,特別是數據工程平臺和數據科學平臺,不就是一種CASE工具、一種針對大數據軟件開發的特殊CASE工具么?這種特殊的CASE工具,目標是讓計算機幫助人更優質、更高效地開發大數據應用這種特殊的軟件。如何幫助人?關鍵的兩點:一是智能化、二是工程化。所謂智能化,就是在工具中固化人的方法論和知識經驗,就是讓工具使用最先進、最智能的模型算法,就是讓工具的數據和知識產出更符合人的認知方式和認知習慣,使得數據處理、數據分析更加高效。所謂工程化,就是大數據應用的開發維護要遵循軟件工程的基本原理,工具要支持設計和實現的一致性,工具要支持配置管理、軟件測試、持續集成等,軟件過程和軟件資產要受管受控,使得大數據應用軟件更加優質。
融合了智能化和工程化的五層架構整合到一塊,為金電聯行實現核心競爭力從技術上提供了有力支撐。其效果就是:可以幫助客戶低成本、高質量地建設決策支持系統。低成本是由于所有核心和基礎的軟件構件開發工作都提前完成了,有各種預制件,包括實現數據處理的預制件、實現數據建模的預制件、實現數據展示的預制件等等,只是根據客戶需求做不同的編排組合,編碼層級的軟件開發工作量大大減少,省人省時。高質量是由于大部分功能和流程都是預制件,而且是抽象層級很高的預制件,軟件質量在預制過程中已經確認,所以整個系統的質量很高。比方說我們給某個政府機構做一個重點企業監測系統,傳統建設方式要兩三個月,可我們使用五層架構,編排預制件,兩三周就高質量交付了,獲得客戶好評。
事實上,我們給金融機構、政府、產業等客戶交付的各種決策支持系統,都是采用同樣的五層架構,只不過是不同的業務需求、不同的數據輸入、不同預制件的不同編排組合、不同的模型輸出、不同的用戶界面。這就類似于收音機的生產方式變革,最早是電子管的,后來是晶體管的,再后來是集成電路的,現在是智能手機里面的一個應用程序,也被叫做軟件無線電;當然智能手機里還有其他程序。決策支持系統建設也是如此,我們開始時模塊化,后來是縱向封裝,現在是五層架構。我們稱其為大數據應用能力的芯片級輸出、平臺級封裝。正是基于這種能力,金電聯行可以隨時切換應用場景,以一套產品和技術體系架構,低成本和高質量地滿足金融、政務、產業等不同領域,不同客戶的不同需求。這樣一種系統建設模式變化是革命性的,為客戶創造了價值,得到了市場認可。

下面在五層架構框架下,談談數據建模和數據科學平臺,它們是大數據應用能夠“從數據挖掘知識,使用知識創造價值”的關鍵環節所在。
所謂數據建模,就是從數據中探尋客觀世界的真理。從本質上講,數據建模體現了一種潛藏在人性深處的駕馭數據的需要,或者說是本能:從積極方面講,人類通過數據建模滿足好奇心;從消極方面講,人類通過數據建模尋求安全感。具體到我們的客戶,他們期望能夠通過數據建模,洞察業務特點規律,以支撐決策、防范風險。具體而言:
決策是數據建模的目標。可以從兩個維度考察決策的特征:一個維度是決策的復雜性,一個維度是決策的風險性。決策的復雜性包括:決策的環境是否確定、決策的信息是否完備、決策的目標是否單一、決策的時間是否充足等等,這些決定了決策的難易程度。單從環境是否確定、信息是否完備而言,AlphaGO做的是簡單決策,股票投資做的是復雜決策。決策的風險可以分為低、中、高,它代表了決策的利害相關程度,例如投資是高風險決策,外部環境越不確定、投資額越大風險越大,當然收益也越大;相對而言,商品推薦是低風險決策。
數據是數據建模的輸入。同樣可以從兩個維度考察數據的特征:一個維度是數據規模,一個維度是數據質量。數據規模可以分為小、中、大:小規模數據單機內存就可以容納;中規模數據單機硬盤或者小規模計算機集群內存可以容納;大規模數據大規模計算機集群內存和硬盤才可以容納。數據質量包括數據的完整性、數據的準確性、數據的結構化程度、數據的時效性、數據的持續性等等,它們決定了數據加工處理的難易程度。
模型是數據建模的輸出。可以從多個維度考察模型的特征,包括模型的準確性、模型的可靠性、模型的安全性(即抗攻擊性)、模型的可解釋性、模型的時效性、模型的經濟性、模型的公平性等。其中最重要的兩個維度是模型的準確性和模型的可解釋性,簡而言之,就是既要知其然、也要知其所以然。
金電聯行的客群主要集中于金融機構、政府部門和大型企業,我們要幫助他們構建基于大數據的決策支持系統。對于這些客戶,從數據而言,通常是中大規模、中低質量;從決策而言,通常是中高風險、復雜決策;從模型而言,通常要兼顧準確性和可解釋性。需要特別強調,這些客戶風險厭惡程度相對偏高。心理學有個著名的前景理論,講的是人都有所謂的“損失厭惡性”。這些客戶尤其如此。由于決策的利害相關性,永遠是合規第一、安全第一、可控第一,可以不使用大數據模型、不獲得大數據模型帶來的收益,但是不可以因為使用大數據模型,而產生不可預測的風險,即便是相對小的發生概率。大數據模型必須要有助于防范風險,而不是帶來未知風險。在很多應用場景下,客戶不會接受由成千上萬特征和成千上萬規則構成的黑盒機器學習模型,必須把黑盒模型打開成白盒模型。客戶要的是:在業務知識規律約束下的大數據模型,也就是可以把控的大數據模型,當然成本要盡可能低、性價比要盡可能高。這就是我們面對的市場。
基于這樣的市場認知,金電聯行研發了“全智”數據科學平臺,幫助客戶低成本、高質量、工程化地構建“既知其然、也知其所以然”的大數據模型。除了常規數據科學平臺的共性之外,“全智”數據科學平臺的特色在于實踐了以人為本、人機融合的建模理念,既依靠人,又服務人。所謂依靠人,就是通過知識圖譜、因果推斷、機器教學等技術途徑,在建模平臺中固化業務專家以及建模專家的方法論和知識經驗,同時結合最先進的自動建模算法,使得建模過程更規范、更高效、更智能、更經濟。所謂服務人,就是使用模型可視化、白盒模型構建、黑盒模型解釋等技術途徑,使得建模成果能夠以方便人理解使用的方式輸出,不僅向人輸出模型,而且向人輸出模型解釋,以幫助人實現業務洞察。實踐表明,“全智”數據科學平臺的技術理念是務實的,適合了市場需求,得到了客戶肯定,對于大數據和人工智能技術在各領域、各行業落地實施,發揮了技術引領和推動的作用。
謝謝大家!